
L’IA comprend-elle le monde ?
ou seulement nos phrases ?
IA
Sylvain Morizet
4/15/20267 min read
Chaque mois, ou presque, une nouvelle démonstration vient relancer le même vertige. Les modèles de langage réussissent des examens complexes, produisent des textes d’une fluidité saisissante, détectent parfois des signaux faibles passés à côté de spécialistes, et donnent le sentiment d’un franchissement historique. À force de performances, une idée s’installe : nous aurions enfin créé une intelligence. Ou du moins quelque chose qui lui ressemble suffisamment pour que la distinction cesse d’importer.
C’est précisément là qu’il faut ralentir.
Car la question essentielle n’est peut-être pas de savoir si ces systèmes sont impressionnants. Ils le sont. La vraie question est ailleurs : que comprennent-ils réellement du monde ? Et surtout : que manque-t-il encore à une machine pour passer de la manipulation brillante de symboles à une authentique prise sur le réel ? Sur ce point, Yann LeCun défend depuis plusieurs années une thèse claire : l’intelligence ne se réduit pas au langage, et la prochaine rupture ne viendra sans doute pas d’un LLM plus gros, mais d’un système capable de se construire un véritable « modèle du monde ».
Le malentendu de notre époque
Nous vivons un moment étrange : plus les modèles parlent bien, plus nous avons tendance à leur attribuer une compréhension profonde. C’est un vieux piège. Quand une machine formule une explication convaincante sur la gravité, sur un dilemme moral ou sur la causalité, nous oublions facilement qu’elle n’accède pas au monde lui-même, mais à des représentations du monde sous forme de données, de textes, d’images ou de corrélations statistiques.
Autrement dit, elle ne touche pas la réalité : elle en parcourt les traces.
Cette distinction paraît abstraite. Elle est pourtant décisive. Un système peut très bien produire une réponse cohérente sur une tasse posée au bord d’une table, citer Newton avec élégance, et rester incapable de « comprendre » ce qu’est une chute au sens physique du terme. Il peut réciter le scénario de la chute sans jamais en posséder l’intuition. C’est tout le cœur du débat actuel sur les limites des modèles génératifs.
Le paradoxe de Moravec, toujours vivant
C’est ici qu’intervient une idée ancienne, mais redevenue brûlante : le paradoxe de Moravec. Il énonce quelque chose de contre-intuitif : les tâches que nous jugeons intellectuellement nobles ou difficiles — calcul, logique formelle, jeu d’échecs — sont souvent plus faciles à automatiser que celles qui nous paraissent évidentes, presque triviales, comme se déplacer dans l’espace, manipuler un objet, percevoir un danger, comprendre une scène ou anticiper un mouvement.
Un enfant de deux ans comprend en quelques essais qu’un objet tombe, qu’un obstacle bloque, qu’un équilibre est instable. Cette compréhension n’est pas verbale. Elle est sensorielle, incarnée, causale. Elle se forme dans l’interaction avec le monde, pas dans la lecture de millions de pages.
Or c’est précisément là que les modèles actuels montrent leur limite. Ils excellent dans l’espace symbolique, mais restent fragiles dès qu’il s’agit d’appréhender la dynamique physique, la permanence des objets, les interactions concrètes, ou simplement ce que signifie agir dans un environnement contraint.
Le langage n’est pas le monde
La Silicon Valley a répondu jusqu’ici par une stratégie simple : plus de données, plus de calcul, plus de paramètres. Cette logique de scaling a effectivement produit des progrès spectaculaires. Elle n’est pas un fantasme : elle fonctionne. Mais elle n’épuise pas le problème. Le fait qu’un modèle réponde mieux n’implique pas qu’il comprenne au sens fort. Cela peut aussi signifier qu’il imite de mieux en mieux les formes discursives de la compréhension.
Yann LeCun, lauréat du prix Turing pour ses travaux fondateurs sur les réseaux convolutifs, défend depuis longtemps l’idée que cette trajectoire n’est pas suffisante. Pour lui, apprendre à penser ne consiste pas à deviner le mot suivant, mais à simuler les conséquences d’une action : si je pousse, si je tourne, si je lâche, que se passe-t-il ? L’intelligence véritable ne serait donc pas d’abord une affaire d’éloquence, mais de causalité.
Cette idée mérite qu’on s’y arrête. Car elle introduit une différence majeure entre deux régimes de l’IA : celle qui imite, et celle qui anticipe.
De l’IA qui génère à l’IA qui simule
Les systèmes génératifs dominants reconstruisent le monde à partir de ses apparences. Ils prédisent des pixels, des tokens, des séquences plausibles. C’est déjà considérable. Mais cette logique atteint vite ses limites lorsqu’il s’agit d’agir dans le réel. Un robot n’a pas seulement besoin de « voir » une assiette : il doit en anticiper le poids, la fragilité, la prise possible, le risque de collision, la dynamique d’ensemble. Une voiture autonome n’a pas seulement besoin d’identifier un ballon sur la route : elle doit inférer qu’un enfant pourrait surgir juste après.
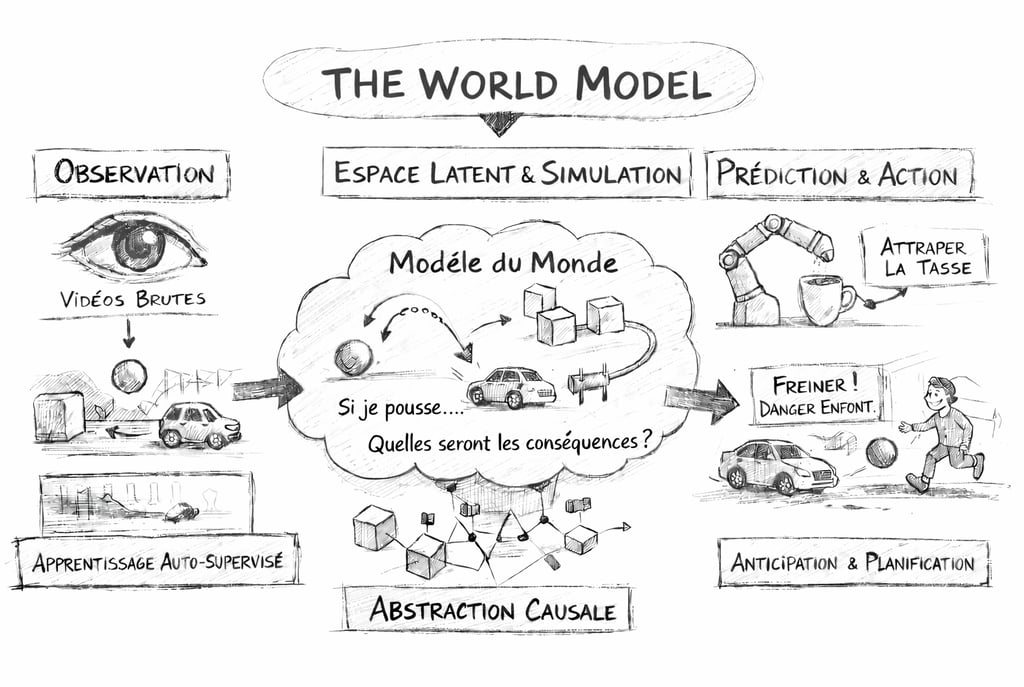
C’est là qu’intervient la notion de world model. Au lieu de reconstruire image après image ou mot après mot, il s’agit d’apprendre une représentation interne suffisamment abstraite pour capturer les variables qui comptent vraiment pour l’action : trajectoires, contraintes, causalités, transitions d’état.
En 2025, Meta a présenté V-JEPA 2 comme un world model vidéo capable d’apprentissage auto-supervisé, de compréhension et de prédiction, avec des résultats de planification et de contrôle robotique en zero-shot sur certains benchmarks. L’idée générale est déjà là : prédire dans l’espace des représentations plutôt que dans celui des pixels.
Pourquoi JEPA change le cadre
LeCun défend une famille d’architectures appelée JEPA, pour Joint Embedding Predictive Architecture. L’idée, formulée simplement, consiste à ne plus demander au modèle de tout régénérer, mais de prédire, dans un espace latent, les aspects pertinents d’une situation future. On ne redessine pas intégralement la balle qui tombe ; on apprend la logique de sa trajectoire. On ne reconstruit pas chaque détail inutile d’une scène ; on isole ce qui est décisif pour l’action et pour la prévision.
C’est une différence philosophique autant que technique. On passe d’une IA du rendu à une IA de la structure. D’une intelligence fascinée par la surface à une intelligence orientée vers les invariants.
Dans un environnement réel, cette différence est immense. Quand nous traversons une rue, nous ne calculons pas le mouvement de chaque feuille d’arbre ni la réfraction sur chaque flaque d’eau. Nous extrayons spontanément les variables critiques. Nous simulons les trajectoires pertinentes. Toute cognition utile est, au fond, une réduction stratégique du monde.
Une preuve de concept plus frugale qu’on ne l’imagine
Un article publié en mars 2026 sur arXiv, intitulé LeWorldModel, va précisément dans cette direction. Les auteurs y présentent un world model de 15 millions de paramètres, entraînable sur un seul GPU, avec un apprentissage de bout en bout à partir de pixels bruts, sans passer par les bricolages habituels de stabilisation. Leur approche repose sur une JEPA couplée à un régularisateur destiné à éviter l’effondrement des représentations latentes. Le papier affirme des performances compétitives en contrôle et une planification bien plus rapide que certaines approches concurrentes fondées sur des représentations plus lourdes.
Il faut rester rigoureux : nous ne sommes pas devant une intelligence générale. Nous sommes devant une preuve de concept. Mais une preuve de concept importante, parce qu’elle suggère qu’un saut qualitatif est possible sans passer uniquement par le gigantisme aveugle.
Autrement dit, la question n’est peut-être plus seulement « combien de paramètres ? », mais « quelle architecture pour quel type d’intelligence ? ».
Le vrai enjeu : sortir de l’illusion discursive
Le problème des LLM n’est pas simplement qu’ils hallucinent. Le problème est plus profond : ils n’ont aucun tribunal interne du réel. Lorsqu’ils se trompent, ce n’est pas un détail cosmétique à corriger version après version. C’est le symptôme d’un rapport au monde médié par des représentations qui ne suffisent pas à valider la vérité physique ou causale d’un énoncé.
Une IA générative produit. Elle ne vérifie pas intrinsèquement. Elle n’a pas de sol.
C’est pourquoi l’enjeu du world model dépasse la seule robotique. Il touche à la possibilité même d’une intelligence artificielle fiable dans les contextes où l’erreur n’est pas tolérable : conduite, chirurgie, assistance industrielle, environnement domestique, agents décisionnels opérant dans des contextes ouverts.
Le milliard de dollars qui dit quelque chose de l’époque
Ce débat théorique a désormais un versant industriel. En mars 2026, AMI Labs, nouvelle entreprise cofondée par Yann LeCun après son départ de Meta, a levé 1,03 milliard de dollars sur une valorisation pre-money de 3,5 milliards, avec l’ambition explicite de construire des world models. La somme est spectaculaire, mais le signal l’est plus encore : une partie de l’écosystème commence à parier sur une sortie du paradigme purement langagier.
Cela ne signifie pas que les LLM vont disparaître. Ils resteront des interfaces extraordinaires, des outils cognitifs puissants, des machines de compression symbolique très utiles. Mais il devient de plus en plus clair qu’ils ne constituent probablement pas, à eux seuls, la voie royale vers une intelligence capable d’habiter le monde.
Ce que cette bascule change pour nous
Au fond, cette histoire révèle quelque chose d’assez humain. Depuis deux ans, nous avons été hypnotisés par la maîtrise du langage. C’est compréhensible : parler, argumenter, écrire, résumer, conseiller, tout cela ressemble à l’intelligence parce que notre culture a longtemps identifié l’esprit à ses productions discursives.
Mais la vie réelle ne se réduit pas à des phrases bien formées.
Comprendre, ce n’est pas seulement répondre. C’est anticiper. C’est éprouver des contraintes. C’est relier une action à ses conséquences. C’est disposer d’un modèle interne suffisamment robuste pour ne pas être dupe des apparences.
En ce sens, l’avenir de l’IA pourrait bien dépendre moins de sa capacité à mieux parler que de sa capacité à mieux se taire pour mieux percevoir.
Et c’est peut-être là le retournement le plus intéressant : après avoir cru que l’intelligence artificielle culminait dans le langage, nous redécouvrons qu’elle commence peut-être dans le rapport au monde.
Réseaux Sociaux & Cie
Rejoignez-nous sur les réseaux sociaux suivants
RESTONS EN CONTACT
© 2024. All rights reserved.